2021年4月份,在byted客服做的一次部门技术分享。
1. VMs vs Containers
VMware provides one of the more elegant virtual machine definitions when they describe a VM as “a software computer.”
- 随着物理机性能和功耗的提升,虚拟化技术的出现是为了榨干物理机资源、提升使用效率。
- 环境隔离、更高效的服务器资源调配、改进的故障恢复能力(例如:OS重启不需要硬件自检了)
- 通过软件模拟出一套特殊的硬件系统(hardware system),然后在其上运行操作系统。即VMware说的software computer。
- 虚拟化的设备+特殊驱动
- A hypervisor, or a virtual machine monitor, is software, firmware, or hardware that creates and runs VMs.
- Hardware虚拟化:Intel® Virtualization Technology (Intel® VT) 技术,提升性能和隔离安全性
1.1 虚拟化的分类
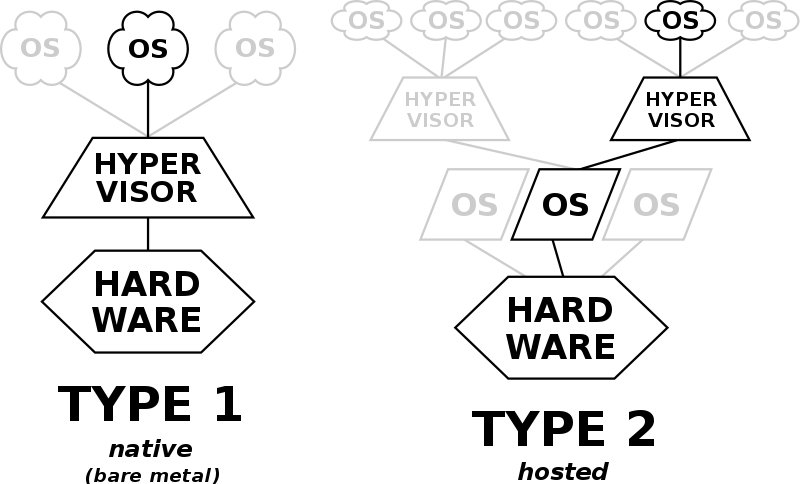
There are two basic ways to run virtual machines: using “Type 1” virtualization or “Type 2” virtualization.
- Type 1 virtualization, a lightweight operating system known as a hypervisor is installed on a physical computer or server. The physical box is often called “bare metal“ and Type 1 hypervisors are often called “bare metal hypervisors. hypervisor直接安装在物理机上。
- Type 2 hypervisors, a.k.a. “hosted hypervisors,” operate a bit differently. As opposed to being installed on top of bare metal hardware, they’re installed on top of a standard operating system. hypervisor安装在操作系统之上。
1.2 虚拟化和容器的区别
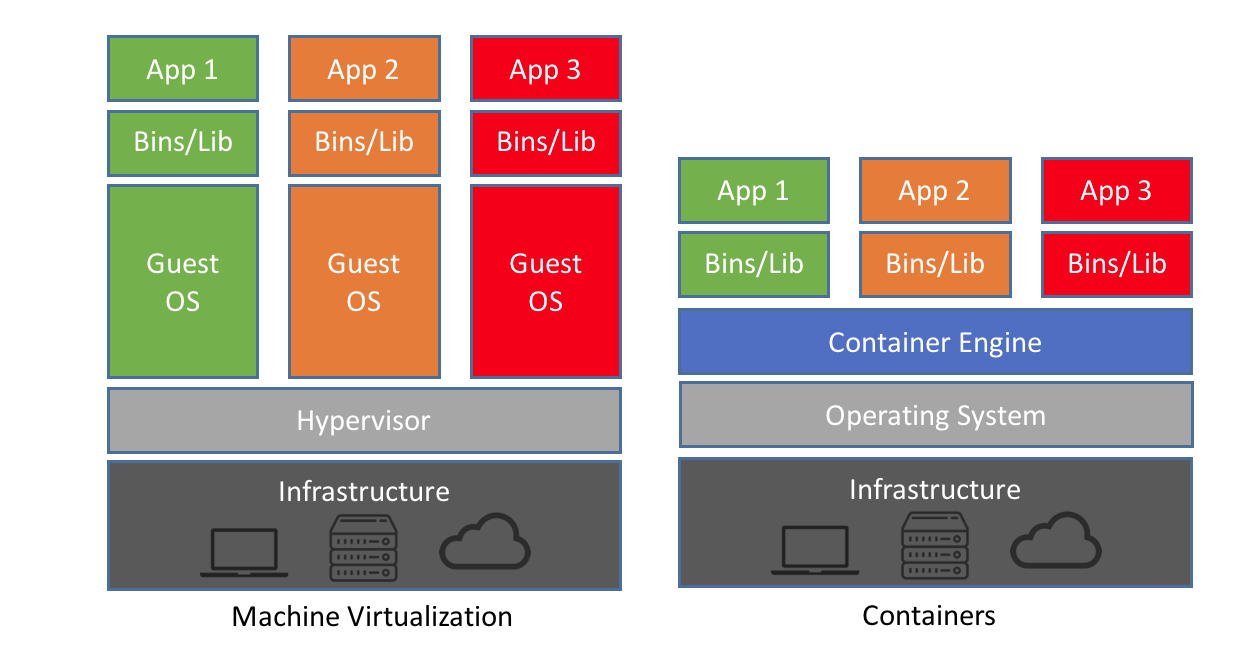
- VMs:共享基础设施,隔离OS
- Containers:共享基础设施&OS,隔离应用
- 相同点:isolated environment for app
2. 什么是容器?
OS层的虚拟化,让在同一个linux kernel里的一组进程,感觉自己运行在独立的虚拟机上(实际却不是)。
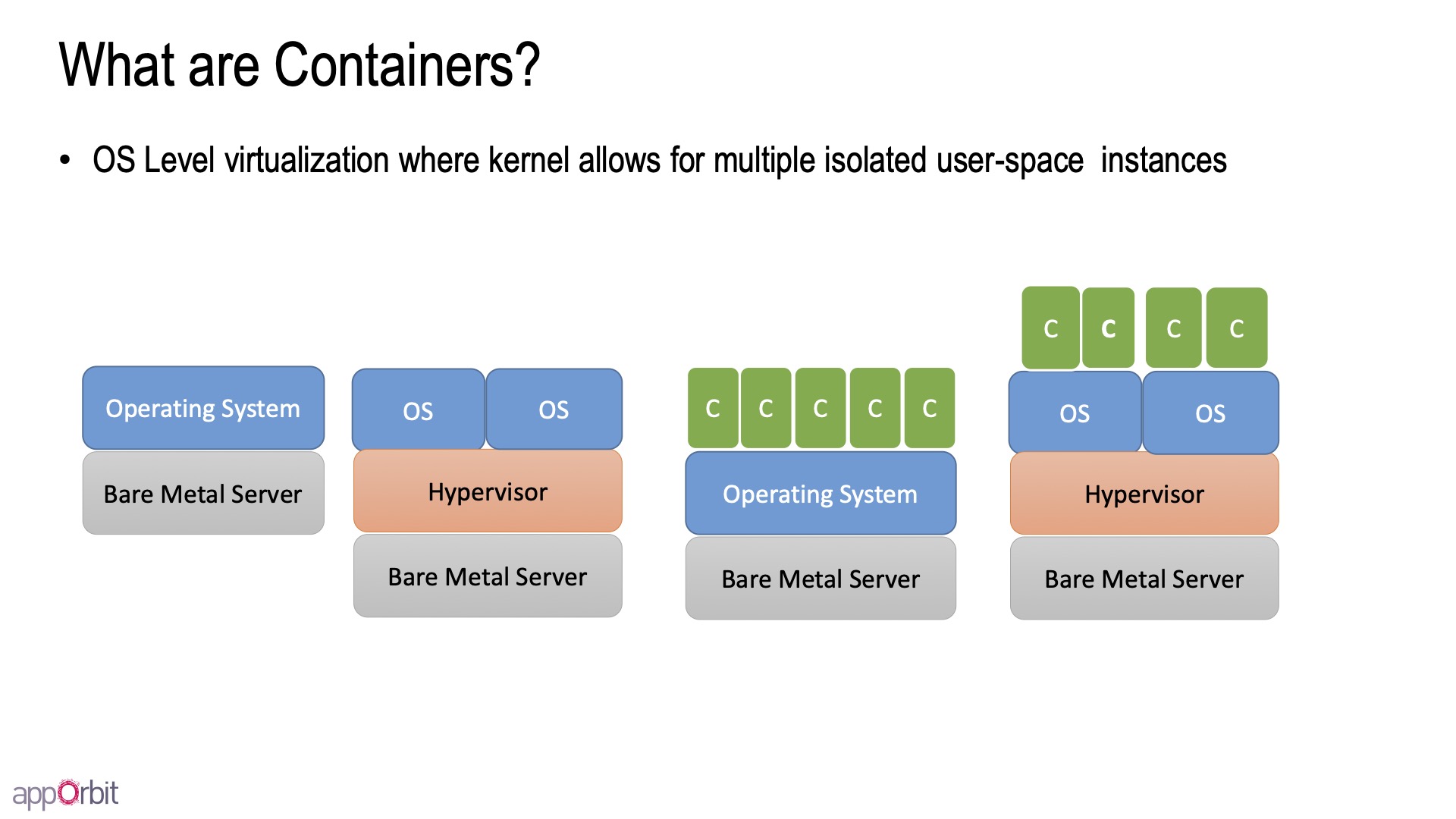
- Containers share the host kernel:不能启动不同的OS(例如:linux上跑windows容器),在host上ps能看见所有进程
- Containers use the kernel ability to group processes for resource control
- Containers ensure isolation through namespaces
- Containers feel like lightweight VMs (lower footprint, faster), but are not Virtual Machines!
电影《楚门的世界》:你不是在另一个星球。
3. 容器的基石:Linux kernel features
3.1 namespaces - limits what you can see 隔离进程的工作空间
给进程提供各自独立的系统视图(system view),看不见、摸不着,从而实现隔离:
- PID namespace for process isolation.
- NET namespace for managing network interfaces.
- IPC namespace for managing access to IPC resources.
- MNT namespace for managing filesystem mount points.
- UTS namespace for isolating kernel and version identifiers.
- User namespace for managing a distinct set of UIDs, GIDs and capabilities.
例如 NET namespace:独立私有的network stack
- network interfaces
- routing tables
- iptables rules
- sockets (ss,netstat) :同个host上重复绑定相同的端口的能力
3.2 cgroups - limits how much you can use 限制进程的资源使用
Control cgroups, usually referred to as cgroups, are a Linux kernel feature which allow processes to be organized into hierarchical groups whose usage of various types of resources can then be limited and monitored. The kernel’s cgroup interface is provided through a pseudo-filesystem called cgroupfs. Grouping is implemented in the core cgroup kernel code, while resource tracking and limits are implemented in a set of per-resource-type subsystems (memory, CPU, and so on).
A cgroup is a collection of processes that are bound to a set of limits or parameters defined via the cgroup filesystem.
cgroups用于限制、审计(accounting for)和隔离一组进程的资源使用情况
- Resource metering and limiting (CPU, memory, block I/O, network, etc)
- Device node access control
- Crowd control
3.3 unshare 命令
1 | $ unshare --help |
4. 容器的基石:Union Filesystem
namespaces & cgroups 提供的是运行时的system view,还需要隔离文件系统:Bins/Lib。
在Docker之前,当LXC创建一个容器时会同时创建一个完整的文件系统拷贝,这会很慢且占用很多空间。Docker基于UnionFS创建一种分层的镜像格式解决了这个问题。
Unionfs is a filesystem service for Linux, FreeBSD and NetBSD which implements a union mount for other file systems. It allows files and directories of separate file systems, known as branches, to be transparently overlaid, forming a single coherent file system. Contents of directories which have the same path within the merged branches will be seen together in a single merged directory, within the new, virtual filesystem.
镜像是一种分层只读(除了最后一层)的文件系统格式,通过镜像来实现容器初始运行环境的定制隔离:
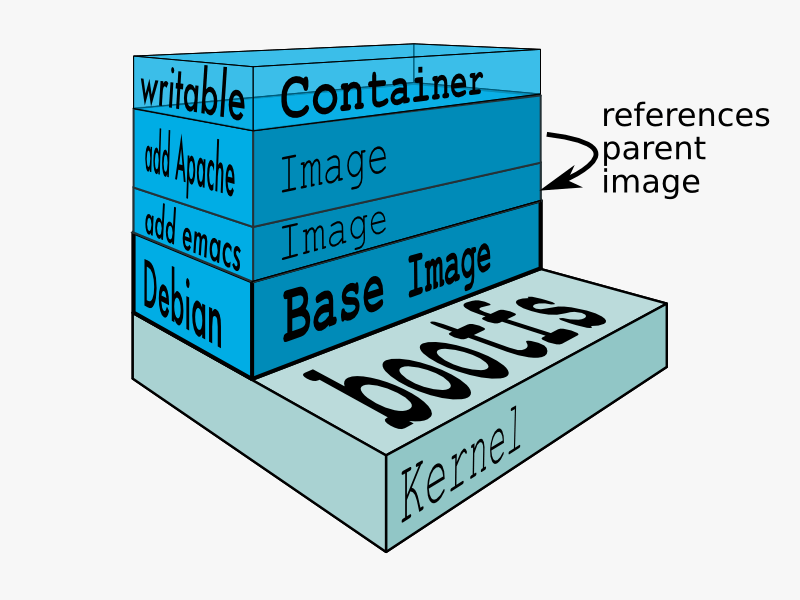
1 | $ docker pull hub.byted.org/base/debian.stretch.jdk8 |
镜像优化tips:
- layer堆叠:所以,在底层layer中存在的文件,即使上层layer中删除,也还是在镜像中。
- 每层layer指令生成一个layer,指令中可以包含多个命令:优化layer大小。
- 镜像的拉取是按layer的:GoogleContainerTools/jib 优化分层
基于镜像+UnionFS,容器实现了文件(Bins/Lib)的共享(系统)和隔离。
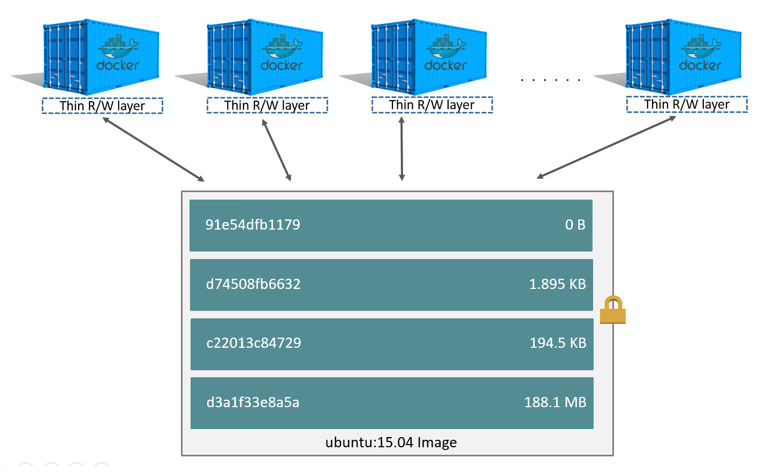
但容器运行时对于文件系统不可能只是只读,可能会修改基础镜像中已有的文件(更新软件),这又是通过copy-on-write来实现。
4.1 Copy-on-write(COW)
Copy-on-write (COW), sometimes referred to as implicit sharing or shadowing, is a resource-management technique used in computer programming to efficiently implement a “duplicate” or “copy” operation on modifiable resources.
容器读取一个在某层只读layer的文件时,可以直接读取(share),当对其修改时会拷贝后再修改(copy),同时shadow掉原来的文件:原来的还在,只是容器看不见了。
- Sharing promotes smaller images
- Copying makes containers efficient
5. Benefits
- 标准化打包软件及其依赖(image):标准化运行环境,可移植性好。如java服务+jdk
- 隔离服务运行环境(container):轻量级,高效、快速(等同于直接启动进程啊,同志们!)
- 赋能微服务
6. Questions
- 镜像中,文件删除怎么做到的?whiteouts
- 容器里运行的服务需要存文件怎么办?
- 有了容器还需要虚拟化么?
- 容器运行的host OS,直接部署在物理机上好,还是部署在物理机上的VM之上更好?
- 2个分别运行在同个物理机上的2个虚拟机里的进程 vs 2个运行在同个OS里的容器进程,在相互影响上有什么区别?
- 容器内的ulimit和host的ulimit什么关系?
7. references
7.1 Containers vs VMs
- https://en.wikipedia.org/wiki/Hypervisor
- https://www.vmware.com/topics/glossary/content/hypervisor
- https://blog.netapp.com/blogs/containers-vs-vms/
- https://www.padok.fr/en/blog/container-docker-oci
- https://www.cbtnuggets.com/blog/certifications/cloud/container-v-hypervisor-whats-the-difference
- https://www.intel.com/content/www/us/en/virtualization/virtualization-technology/intel-virtualization-technology.html
- https://blog.resellerclub.com/what-is-a-hypervisor-and-how-does-it-work/
7.2 Container Internals
- https://en.wikipedia.org/wiki/OS-level_virtualization
- https://linuxcontainers.org/
- http://docker-saigon.github.io/post/Docker-Internals/
- https://delftswa.github.io/chapters/docker/
- http://dockone.io/article/2941
- https://jvns.ca/blog/2016/10/10/what-even-is-a-container/
- https://www.slideshare.net/jkshah/postgresql-and-linux-containers
- https://www.slideshare.net/RohitJnagal/docker-internals
- https://www.slideshare.net/jpetazzo/cgroups-namespaces-and-beyond-what-are-containers-made-from-dockercon-europe-2015
- https://stackoverflow.com/questions/53173669/docker-ulimit-differences-between-container-and-host
- https://medium.com/@BeNitinAgarwal/understanding-the-docker-internals-7ccb052ce9fe
- https://itnext.io/breaking-down-containers-part-0-system-architecture-37afe0e51770
- https://itnext.io/breaking-down-containers-part-1-namespaces-9668b86d003d
- https://medium.com/swlh/docker-and-its-internals-9c7a771be52e
- Getting a Shell in the Docker Desktop Mac VM
7.3 Union Filesystem
- https://itnext.io/deep-dive-into-docker-internals-union-filesystem-5a1fbcd426b5
- https://www.terriblecode.com/blog/how-docker-images-work-union-file-systems-for-dummies/
- https://docs.docker.com/storage/storagedriver/
- https://lwn.net/Articles/324291/
- https://en.wikipedia.org/wiki/Copy-on-write
- https://github.com/opencontainers/image-spec/blob/master/spec.md